
Why URL and Page Structure Matter
If you want Google to like your site, you need to appease Panda and Penguin. Panda is for content, and Penguin is for links. These statements are to SEOs as “plants need water and sunshine” are to botanists. Both of these examples are, of course, overly simplified explanations for complicated phenomena, and there are multiple outliers and variables to each. But as a general practice, SEO is at least partially about appeasing Google, and appeasing Google is at least partially about satisfying Panda and Penguin.
These rules are straightforward enough, but it’s when you dig into the gray areas that things get interesting. I recently found a gray area when it came to the idea of the URL structure and information architecture of websites. A site’s URL structure is like a map of its pages. It can show users which pages relate to other pages, if done correctly, and it can display quite clearly to Google that your site is either a jumbled mess or an organized, streamlined machine that even Danny Tanner would be proud of. (Sorry for the 90’s sitcom reference – I’m pretty new here.)
A URL doesn’t specifically relate to Panda, nor does it specifically relate to Penguin – but it does require a webmaster to consider a few different elements of both algorithms. After experimentation and hard work with a number of clients in different industries, I was able to come up with a few rules of thumb (backed up by Matt Cutts, Rand Fishkin, and various other industry experts and insiders). Beginning with the basics, here is what I learned.
URL Structure: A General Overview
It’s a generally accepted best practice these days that a URL should represent the internal linking path a user took to get to your page. For example, a good URL would look something like:
http://www.example.com/internet-marketing/analytics/
It’s clear that the main path to this page is from the homepage, to the internet marketing page, to the analytics sub-page. This makes it easier for your users (and for your friendly neighborhood GoogleBots) to see where they’ve been, how they got to where they are, and it creates that web-like internal linking structure that everyone likes.
A client we recently took over from another internet marketing company, however, had taken this generally accepted best practice to an uncomfortable extreme. There were layers upon layers of sub-folders in the URL, sometimes as many as 5 or 6. So, for example:
http://www.example.com/internet/marketing/google/analytics/services
Not only did it add confusion to a pretty informative website, but also many of the pages they were leading visitors to were totally unnecessary (while some of the more important pages got ignored and lost in the clutter).
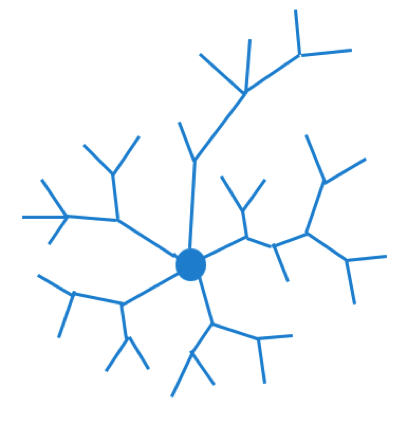
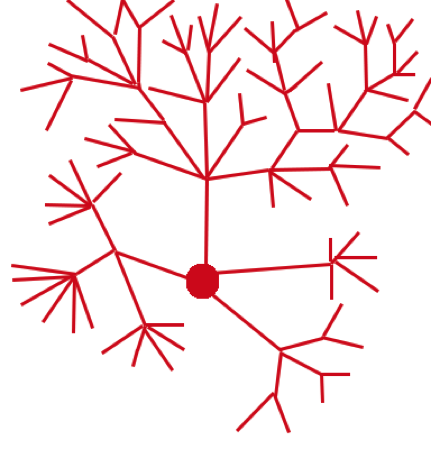
These two images are visual representations of internal linking structures (for sites that are not e-commerce). The blue web is clear and easy to follow – a few pages stem from the homepage, and then a few more pages stem out from those pages. There are, at most, four segments to each path. The red web is more complicated. As many as five or six pages stem out from each path, and there are up to six or seven segments to each path in some places. The blue represents the ideal, whereas the red represents what we dealt with in the case of the client mentioned above.
Cleaning Up Your Clutter
In a recent Whiteboard Friday video, Rand Fishkin explained that subpages are the ideal way to structure your information, but only if the content is unique. In the case of the client above, for example, there were multiple subpages stemming from the “drugs are bad” page (an over-simplification to protect anonymity). Each of the subpages contained the same basic idea – one was “drug A is bad,” one was “drug B is bad,” etc. The laws concerning each drug were not altogether different – all of the drugs are bad, all of them are illegal, and all of them lead to similar consequences.
To fix this issue, I eliminated all of the pages about specific substances and added a brief paragraph about each to the main “drugs are bad” page. This removed an entire sublevel from the URL structure, and more importantly, it told Google that I wasn’t trying to spam them. Google is smart enough to understand a site’s intent and content with less “SEO help” than before. It understands that our page’s content is about the badness of various drugs, without us listing out each particular drug, its chemical makeup, its origins, its history, and its favorite color. When we do, Google doesn’t place as much trust in our content. (Nobody likes to be patronized, GoogleBots included.)
The Sub-pages Clean-up Process
In order to rectify this issue, I created a spreadsheet based on the site’s HTML sitemap. I noted down every page that was listed, its title, and its URL. Then I went through and mapped out a new URL structure, which involved two or three subfolders within the URL at most. This sometimes required consolidating unnecessary pages or changing them into blog posts. Other times it involved evaluating whether content was truly necessary and removing it.
| Current Page Title | Current Page URL | New Parent Page | New Page Title | New Page URL |
| Resources | Example.com/information/resources | (Parent Page) | Resources | Example.com/resources |
| Read Our Newsletters | Example.com/information/resources/read-our-newsletters | Resources | Newsletters | Example.com/resources/newsletters |
| Watch Our Videos | Example.com/information/resources/watch-our-videos | Resources | Videos | Example.com/resources/videos |
| Get Help Now | Example.com/information/get-help-now | (Parent Page) | Contact | Example.com/contact |
Having all of the page’s info laid out, including certain specific components of the URL structure, allowed me to move certain pages out from other pages, eliminate unnecessary subpages, and organize many different aspects of the site (including titles) more clearly.
In the example client’s case, I ended up completely removing a lot of the “drugs are bad” content in order to simplify the URLs and eliminate repetitive and irrelevant subpages. Removing this content also showed Google that this content wasn’t as important as other content on the site. The percentage of drug-based content was much higher than content that related to other aspects of the client’s work, so some of the highest-ranking keywords for the site when we took it over from the previous SEO company were things like “how to buy drug A.” Which is definitely not what you want to see (and definitely not what the client does).
What the Experts Say
I found a lot of helpful hints in a 2010 Webmasters Video. In the video, Matt Cutts says that the number of levels or subfolders in a URL has “virtually no direct impact on SEO whatsoever.” However, he does say that shorter URL structures are generally better for usability, which we know is something Google has been very focused on in 2014. (He also cites page rank as being more important than URL structure, which cannot be true anymore as page rank virtually doesn’t exist).
I also found numerous sources that said that shorter URLs have higher CTR’s than longer ones. This is most likely because of the way Google displays URLs and snippets on its search results page – shorter URLs are fully displayed and don’t trail off. And in a catch-22 sort of way, even if a shorter URL doesn’t directly add ranking value, a higher CTR will definitely contribute to higher rankings over time.
For example, check out the results I got when I searched “Hi Google.”
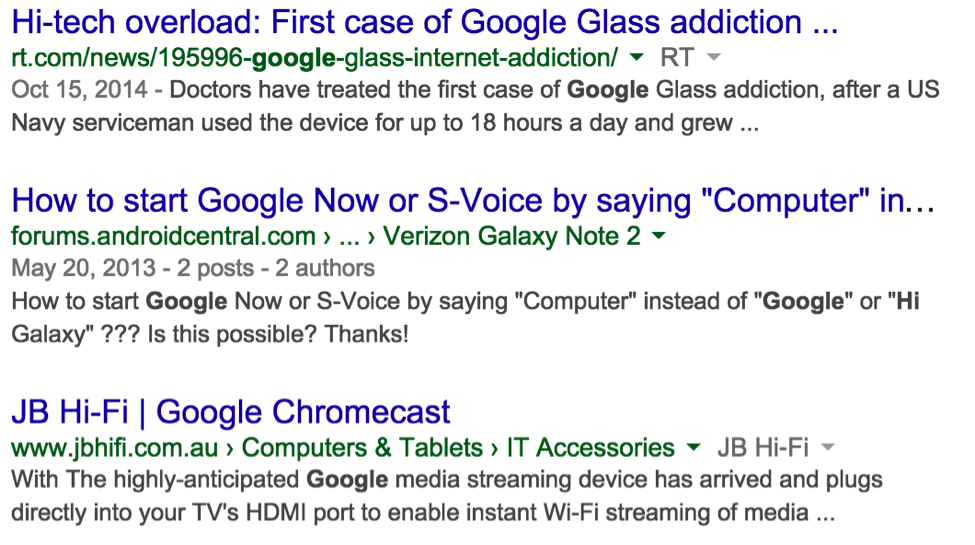
The URLs on the top and bottom are fully displayed in the search results. The one on the bottom gets several canonical tags associated with the URL, where the longer one in the middle only gets one. There are many factors involved in the way a site is displayed on Google, of course, but if there is only room for one tag, there can only be one tag.
It’s worth noting that what works for one client in the case of SEO doesn’t always work for another, but of the four clients for whom I spent time this month cleaning up internal links and URLs, all of them have seen a recent organic boost in analytics.
If you have questions about your site’s URL structure or need help cleaning it up, contact us at Boomtown Internet Group. And if you have your own insights about the importance of shorter, cleaner URLs, comment on this post. I look forward to more information and further discussion about this topic in the future.